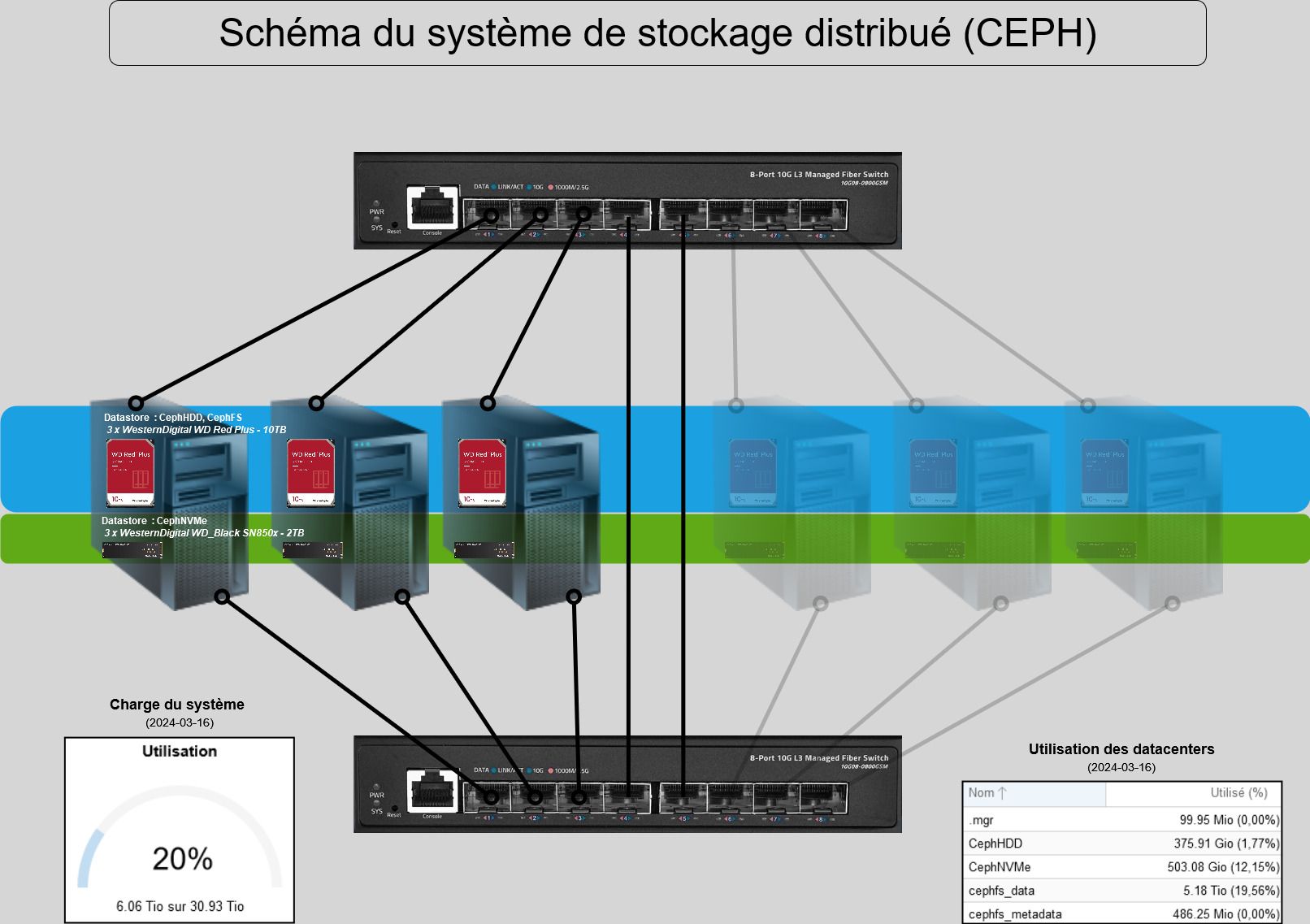
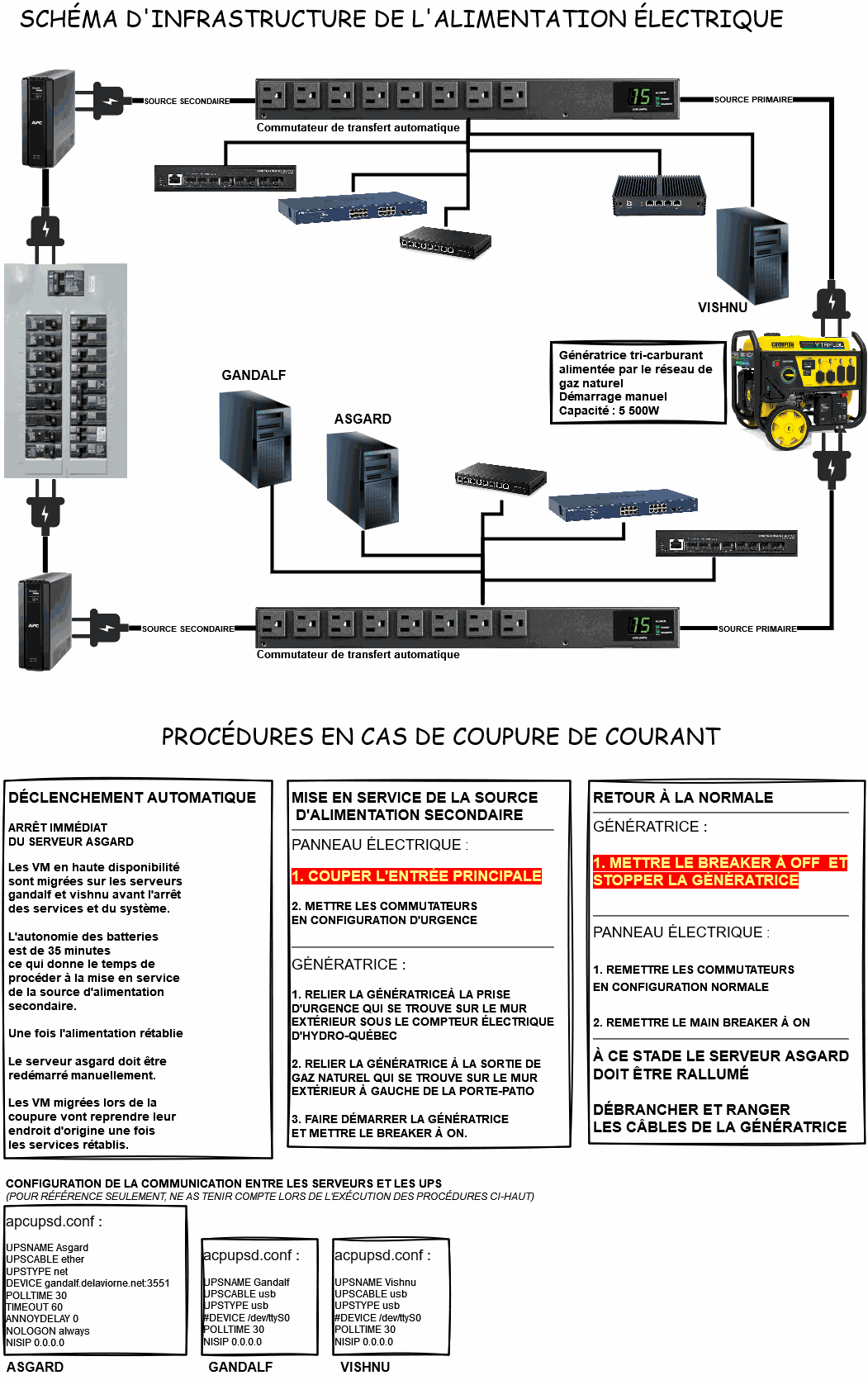
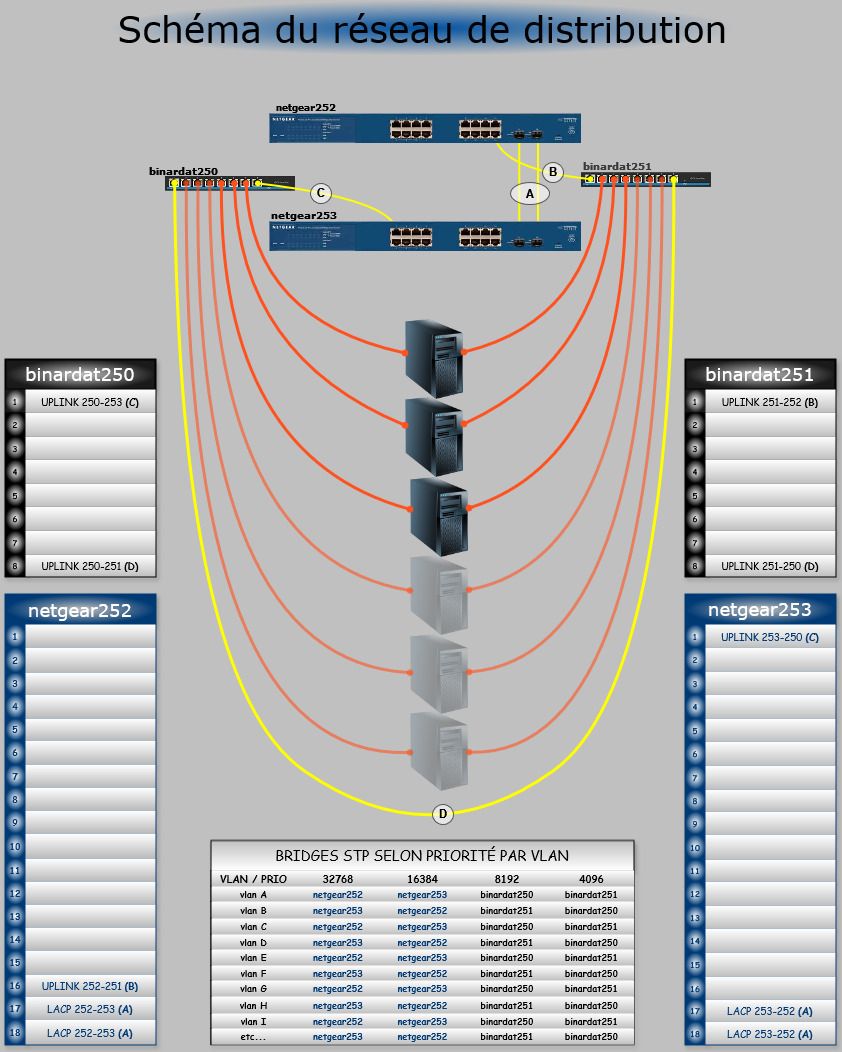
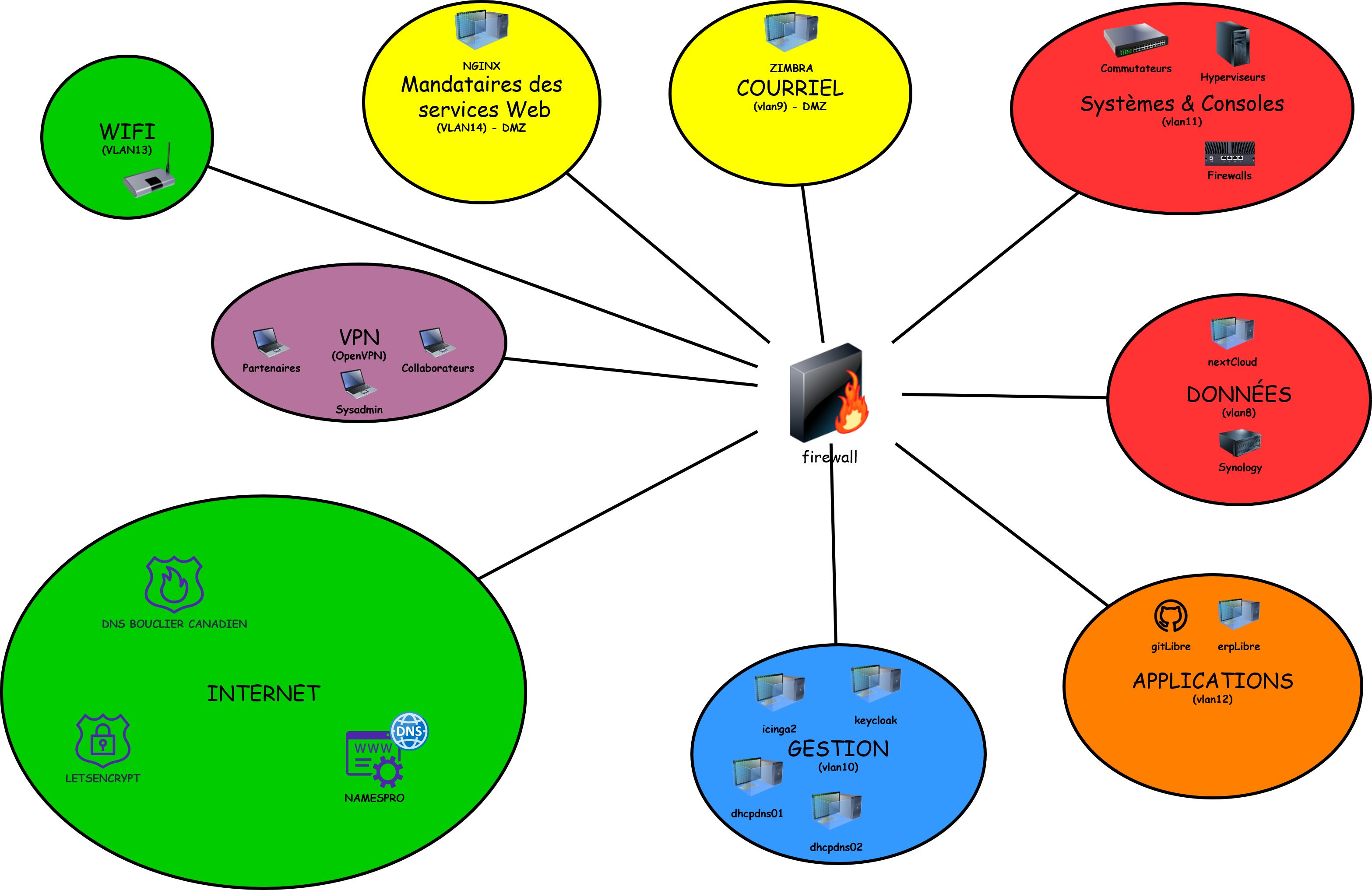
Stratégie de Haute Disponibilité et de recouvrement du Service DNS avec BIND
Configuration Maître-Esclave
La base de ma stratégie repose sur une configuration maître-esclave. Dans cette configuration, il y a deux serveurs DNS - un serveur primaire (maître) et un serveur secondaire (esclave). Le serveur primaire a le droit de lire et d’écrire les données originales de la zone DNS, tandis que le serveur secondaire conserve une copie en lecture seule de ces données. Les mises à jour des zones DNS sont régulièrement transférées du serveur primaire au serveur secondaire.
Cette configuration élimine le point de défaillance unique. Si le serveur primaire tombe en panne, le serveur secondaire peut prendre le relais et continuer à servir les requêtes DNS sans interruption.
Surveillance avec Nagios
Pour surveiller la synchronisation DNS entre les serveurs, j'utilise ICINGA2 et un script Nagios, un outil de surveillance puissant et flexible. Ce script utilise la commande dig pour interroger les serveurs DNS et comparer les numéros de série des zones. Si les numéros de série ne correspondent pas, cela indique un problème de synchronisation, et ICINGA2 génère une alerte pour me permettre de réagir rapidement.
Méthode de recouvrement
En cas de défaillance du serveur primaire, la méthode de recouvrement que j'ai choisie est de restaurer la VM et ensuite de rétablir le service DNS. Cette procédure implique d’augmenter manuellement le numéro de série des zones DNS sur le serveur primaire restauré et de redémarrer le service, ce qui va relancer la mise à jour des zones sur le serveur secondaire. Cela garantit que les deux serveurs ont les données DNS les plus récentes.
Cette stratégie offre une bonne balance entre la fiabilité, la performance et la simplicité de gestion. Elle permet de maintenir un service DNS hautement disponible et fiable, tout en minimisant le risque de perte de données en cas de défaillance du serveur primaire.