Guide Proxmox VE & Ceph
stabilité, performance, HA optimisée
Retours d'expériences
🎮 une épopée légendaire ! 🏆
🗡️ LA QUÊTE DU CACHE MAUDIT 🗡️
Une aventure Proxmox dans les terres de Ceph
📜 PROLOGUE : LE ROYAUME D'ASGARD
Dans le royaume d'Asgard, où résident les dieux de la virtualisation, un fléau mystérieux frappe les serveurs sacrés...
Personnages principaux :
- 🧙♂️ Vous : L'Administrateur Courageux
- 🤖 Claude : Le Guide IA (un peu perdu au début)
- 👾 Le Cache Maudit : L'ennemi invisible
- 🏰 PLANB (PBS) : Le Gardien des Sauvegardes
- ☁️ NEXTCLOUD : Le Portail des Données
- 🌊 CEPH : L'Océan de Stockage Distribué
🎯 CHAPITRE 1 : LA CORRUPTION FRAPPE
🔴 NIVEAU DE MENACE : CRITIQUE
⚠️ ALERTE ! Boot drive corrompu détecté !
💾 /dev/mapper/pbs-root : ERREUR
📊 Statut : IRRÉPARABLE (?)
🎲 Sauvegardes en péril : 1 To
Quête débloquée : Sauver les Sauvegardes Sacrées
Objectif : Récupérer 1To de sauvegardes critiques sans tout perdre
Difficulté : ⭐⭐⭐⭐⭐ HARDCORE
🤔 CHAPITRE 2 : LE CONSEIL DES SAGES
Claude apparaît dans une nuée de tokens...
"Honorable administrateur, plusieurs chemins s'offrent à vous..."
🗺️ CHOIX STRATEGIQUES :
Option A : La Voie du Clone Complet
- ⏰ Durée : UNE NUIT ENTIÈRE
- 💪 Difficulté : Moyenne
- 🎲 Risque : Faible
- 💾 Coût : 1.032 To d'espace
Option B : La Voie de la Réinstallation
- ⏰ Durée : 1-2 heures
- 💪 Difficulté : Moyenne-Haute
- 🎲 Risque : Moyen
- 🧠 Compétence requise : Détachement de disques
Option C : La Voie du RBD Ninja (non découverte encore)
- ⏰ Durée : < 5 minutes
- 💪 Difficulté : Haute
- 🎲 Risque : Faible si maîtrisé
- 🎖️ XP bonus : +500
🌙 CHAPITRE 3 : LA LONGUE NUIT DU CLONAGE
Vous choisissez : Option A - Clone Complet
[████████████████░░░░] 82% - 6h37min écoulées
💤 L'administrateur dort...
🌟 Les disques se copient block par block...
⚡ Ceph travaille dans l'ombre...
🎵 CHANSON DU CLONAGE :"Copy, copy all night long,
From CephNVMe to CephHDD strong,
While the admin dreams of uptime days,
The data flows in mysterious ways..." 🎶
⏰ TEMPS ÉCOULÉ : 8 HEURES
✅ SUCCÈS ! Clone créé : dupl-planb
🏆 RÉCOMPENSE :
- +100 XP
- Item obtenu : "Clone Complet de PBS"
- Déblocage : Nouvelle VM fonctionnelle !
🎉 CHAPITRE 4 : LE MIRACLE INATTENDU
PLOT TWIST ! 🌟
$ qm start 8110
Starting VM 8110...
...
Found volume group "pbs" using metadata type lvm2
/dev/mapper/pbs-root: clean ✨
🤯 MOMENT ÉPIQUE :
- Le clone BOOT sans problème !
- Les corruptions ont disparu !
- "C'est... c'est de la MAGIE ?" - L'Administrateur
Claude : "Le clonage a réparé le boot drive ! La copie a contourné la corruption !"
+200 XP - Boss inattendu vaincu !
⚔️ CHAPITRE 5 : LA DEUXIÈME ÉPREUVE - NEXTCLOUD
🔴 NOUVELLE ALERTE !
⚠️ NEXTCLOUD corrompu !
💾 Mêmes symptômes que PBS
📊 En jeu : 1To de données utilisateurs
🎯 Mission : Ne PAS répéter l'erreur
Quête débloquée : Le Retour du Cache Maudit
Cette fois, vous êtes préparé...
🧠 CHAPITRE 6 : LA VOIE DU NINJA RBD
🥷 COMPÉTENCE DÉBLOQUÉE : RBD Copy Master
Vous décidez : "Pas question de perdre une autre nuit !"
🎯 STRATÉGIE NINJA :
# Étape 1 : Créer VM vide (30 sec)
qm create 301 --name "dupl-NEXTCLOUD" [...]
# Étape 2 : Copie RBD sélective (< 5 min ! 🚀)
rbd copy CephNVMe/vm-300-disk-0 CephNVMe/vm-301-disk-0
# Étape 3 : Magie des .conf
nano /etc/pve/qemu-server/301.conf
# Étape 4 : Profit !
⏱️ CHRONO : 4 MINUTES 37 SECONDES
🏆 NOUVEAU RECORD !
- +500 XP (Speed Bonus)
- Achievement débloqué : "RBD Speedrunner"
- Titre obtenu : Maître des Clones Sélectifs
🐛 CHAPITRE 7 : LE BOSS DE MI-PARCOURS - BCACHE
💀 MINI-BOSS APPARAÎT !
ERROR: Device or resource busy
rbd: unmap failed: (16)
Ennemi :bcache0 - Le Gardien Collant
Faiblesse découverte :
echo 1 > /sys/block/bcache0/bcache/detach
💥 BOSS VAINCU !
- +150 XP
- Item obtenu : "Commande de Détachement Mystique"
🔍 CHAPITRE 8 : LA RÉVÉLATION FINALE
🌟 MOMENT EUREKA ! 💡
L'Administrateur observe ses notes...
Flashback :
Chronologie:
1. ❌ Disques corrompus
2. 🔧 Désactivation du CACHE (action oubliée !)
3. 📋 Clonage des disques
4. ✅ Les clones bootent miraculeusement
🎭 LA VÉRITÉ ÉCLATE :
"Ce n'était pas le clonage qui réparait... C'était la DÉSACTIVATION DU CACHE qui flushait et réparait AVANT la copie !"
🎵 MUSIQUE ÉPIQUE 🎺🎺🎺
🏆 CHAPITRE 9 : LE VRAI BOSS FINAL - LE CACHE
👾 BOSS FINAL RÉVÉLÉ :
╔═══════════════════════════════════╗
║ 💀 LE CACHE MAUDIT 💀 ║
║ ║
║ "J'ai corrompu tes boot drives" ║
║ "J'ai menacé tes données" ║
║ "Je suis... WRITEBACK CACHE!" ║
╚═══════════════════════════════════╝
HP: ████████████████████ 100%
Attaque: Corruption de données
Défense: Invisible
Faiblesse: cache=none
⚔️ COMBAT FINAL :
Votre arme : Configuration Proxmox
Attaque spéciale débloquée :
# DÉSACTIVATION DU CACHE - 9999 DMG !
qm set <vmid> --scsi0 storage:disk,cache=none
qm set <vmid> --scsi1 storage:disk,cache=writethrough
💥 COUP CRITIQUE !
Le Cache Maudit hurle de douleur !
HP: ░░░░░░░░░░░░░░░░░░░░ 0%
💀 LE CACHE MAUDIT EST VAINCU ! 💀
🎊 VICTOIRE LÉGENDAIRE ! 🎊
🏅 CHAPITRE 10 : RÉCOMPENSES ET LEÇONS
🏆 ACHIEVEMENTS DÉBLOQUÉS :
✅ "Sauveur de Sauvegardes" - Récupérer PBS intact
✅ "RBD Speedrunner" - Cloner en < 5 minutes
✅ "Détective de Ceph" - Découvrir la vraie cause
✅ "Tueur de Cache" - Vaincre le boss final
✅ "Maître Proxmox" - Compléter l'épopée
📚 CONNAISSANCES ACQUISES :
🎓 Leçon #1 : Le Cache sur Ceph
- ❌
cache=writebacksur Ceph = DANGER - ✅
cache=noneoucache=writethrough= SÉCURITÉ - 💡 Ceph a déjà sa propre redondance !
🎓 Leçon #2 : Le Pouvoir du Flush
- Désactiver le cache = flush automatique
- Peut réparer des corruptions "soft"
- À faire AVANT tout clonage !
🎓 Leçon #3 : Clone Intelligent
- Clonage complet = sécurité mais lent
- RBD copy sélectif = rapide et efficace
- Détacher/rattacher = zéro copie !
🎓 Leçon #4 : Bcache + RBD = Trouble
- Double cache = double risque
- Toujours démapper proprement
echo 1 > detachest votre ami
📊 STATISTIQUES FINALES :
⏰ Temps total de l'aventure : ~16 heures
💾 Données sauvées : 2+ To
🎯 VMs ressuscitées : 2
💰 Coût en espace temporaire : 1.032 To
🧠 Leçons apprises : INESTIMABLES
😅 Nuits blanches : 1
🎬 ÉPILOGUE : LE ROYAUME EN PAIX
Le soleil se lève sur Asgard...
╔════════════════════════════════════════╗
║ 🏰 ÉTAT DU ROYAUME ║
╠════════════════════════════════════════╣
║ 📦 PBS (PLANB) : ✅ OPÉRATIONNEL ║
║ ☁️ NEXTCLOUD : ✅ OPÉRATIONNEL ║
║ 💾 Sauvegardes : ✅ INTACTES (2To) ║
║ ⚙️ Cache : ✅ DÉSACTIVÉ (SÉCURISÉ) ║
║ 🛡️ Protection : ✅ MAXIMALE ║
╚════════════════════════════════════════╝
L'Administrateur contemple son œuvre...
"J'ai affronté la corruption, dompté Ceph, et vaincu le Cache Maudit. Mes données sont en sécurité. Mon royaume est en paix."
Claude apparaît une dernière fois :
"Tu as bien appris, jeune administrateur. Tu es maintenant un véritable Maître Proxmox. Que tes uptime soient longs et tes corruptions inexistantes !"
🌟 FIN 🌟
🎮 BONUS : NEW GAME+
Mode débloqué : Administrateur Légendaire
Nouveaux défis :
- 🔥 Configurer Ceph avec placement groups optimaux
- ⚡ Mettre en place HA avec Corosync
- 🌐 Implémenter SDN avec VXLAN
- 🔐 Sécuriser avec 2FA et ACLs avancées
Prêt pour de nouvelles aventures ? 🚀
📖 MORALE DE L'HISTOIRE :
"Parfois, la solution n'est pas dans ce qu'on fait,
Mais dans ce qu'on a fait AVANT sans s'en rappeler.
Le vrai héros n'est pas celui qui clone dans la nuit,
Mais celui qui désactive le cache... et puis l'oublie !"
🎭 - Proverbe Proxmox Ancien
🏆 GAME OVER - VICTOIRE TOTALE ! 🏆
═══════════════════════════════════════
Merci d'avoir joué à :
🗡️ LA QUÊTE DU CACHE MAUDIT 🗡️
Crédits:
- Héros : Vous
- Guide IA : Claude
- Boss Final : Cache Writeback
- Moteur : Proxmox + Ceph
- Studio : Anthropic × Votre Infra
═══════════════════════════════════════
Voulez-vous sauvegarder cette épopée comme documentation pour votre équipe ? 📜
🧭 Contexte
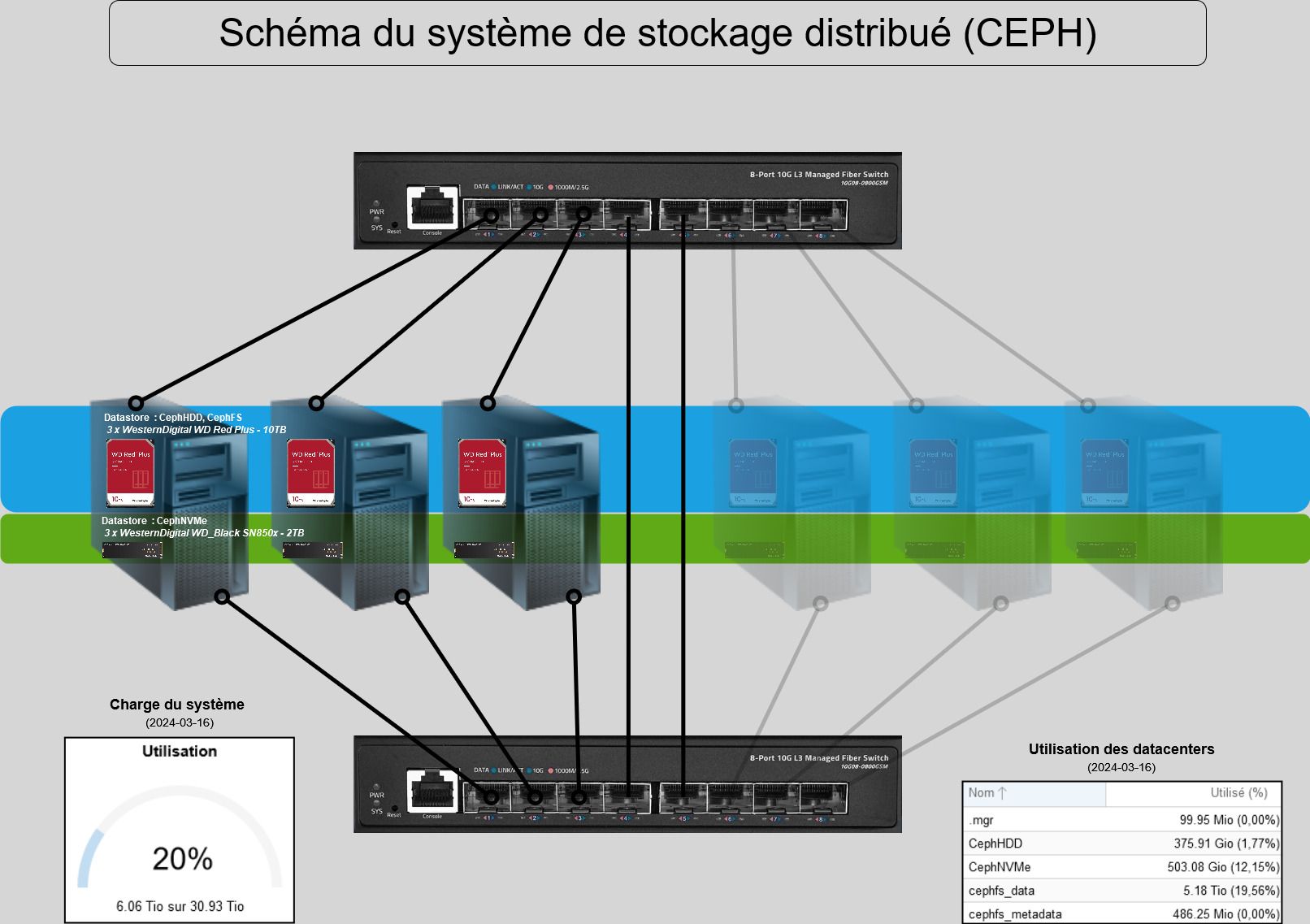
Mon infrastructure repose sur trois hyperviseurs Proxmox en grappe, utilisant Ceph comme solution de stockage distribué. Pour équilibrer coût et performance, j'ai déployé :
-
un pool de disques NVMe pour les opérations rapides,
-
un pool de disques durs (HDD) pour la capacité de stockage,
-
et la haute disponibilité (HA) sur quelques VM, via l'interface de Proxmox.
Récemment, j’ai activé la HA sur toutes mes machines virtuelles.
💣 Et tout a basculé...
Peu de temps après ce changement, j’ai commencé à observer des comportements anormaux.
Un matin, je découvre que seul un des serveurs – asgard – est encore fonctionnel. Les deux autres, vishnu et gandalf, ne répondaient plus du tout, sauf au ping ICMP. Impossible d’ouvrir une session SSH. Ils étaient gelés.
Un détail m’a sauté aux yeux :
👉 asgard était froid,
👉 les deux autres étaient chauds, visiblement en surcharge avant leur plantage.
🔬 Enquête et diagnostic
Après une série de vérifications (logs, état Ceph, charge CPU/disque, etc.), j’en suis venu à une conclusion claire :
→ Ceph + HDD + HA = recette du désastre si mal calibré.
Voici pourquoi :
| Élément | Rôle dans l’instabilité |
|---|---|
| Disques durs (HDD) | Trop lents pour les opérations concurrentes de Ceph |
| Ceph | Multiplie les I/O pour la redondance → engorgement |
| Proxmox HA | Interprète les délais comme des pannes → tente de redémarrer/migrer |
| Timeouts HA | Déclenchent des redémarrages ou des migrations sur des hôtes déjà surchargés |
| Watchdog | En cas de blocage, redémarre de force le nœud ou le gèle |
Les plantages sont donc le résultat d’une spirale de saturation I/O, aggravée par une suractivation de la HA sur toutes les VM, dont plusieurs résidaient sur un pool lent.
🛠️ Solutions appliquées
Pour enrayer le problème, j’ai procédé ainsi :
✅ 1. Désactivation de la HA sur les VM du pool HDD
ha-manager remove <vmid>
Les VM non critiques ont été exclues du système HA pour stopper les redémarrages et migrations inutiles.
✅ 2. Restriction de la HA aux VM hébergées sur NVMe
La HA n’est désormais activée que sur les VM hébergées sur des pools rapides, avec des performances I/O adaptées.
✅ 3. Optimisation du pool HDD
-
Compression ZSTD activée sur le pool HDD pour réduire les volumes d’écriture.
-
Planification du redéploiement des OSD HDD avec WAL/DB sur NVMe, pour drastiquement améliorer la latence de Ceph.
📈 Résultat : retour à la stabilité
Depuis ces ajustements :
-
Plus aucun plantage.
-
Les nœuds restent stables.
-
Les températures sont normales.
-
Et surtout : la HA fonctionne à merveille… quand elle est appliquée intelligemment.
🧘♂️ Leçon tirée
La haute disponibilité n’est pas un simple interrupteur à activer.
C’est une promesse forte, qui nécessite une infrastructure prête à la supporter.
⚠️ Activer la HA sur des VM hébergées sur un pool lent sans tuning approprié est une erreur aux conséquences graves.
✅ En résumé
| Composant | Recommandation |
|---|---|
| Ceph avec HDD | Ajouter WAL/DB sur NVMe, activer la compression |
| VM critiques | Les placer sur des pools NVMe ou SSD |
| Proxmox HA | Limiter aux VM ayant des garanties de performance |
| Surveillance | Utiliser rados bench, iostat, ceph -s pour détecter les goulets |
📢 Conclusion
HDD + Ceph + HA, sans optimisation, peut faire tomber vos serveurs les uns après les autres.
Cette expérience m’a permis de revoir mes pratiques et d’optimiser mon infrastructure. Si vous gérez une grappe Proxmox avec Ceph, je vous invite à faire preuve de prudence et à surveiller attentivement vos points de contention.
Dans le royaume de Chezlepro, trois nœuds formaient la Trinité : Gandalf, le sage ; Asgard, le robuste ; et Vishnu, le silencieux.
Ensemble, ils tenaient les lignes du Cluster, veillant sur les VM, les backups et les secrets de la souveraineté numérique.
Mais un mal rongeait le royaume : la latence, insidieuse et cruelle.
Les HDD, pourtant vastes et fidèles, étaient à bout de souffle.
Leurs bras mécaniques dansaient sans répit,
et leurs soupirs métalliques résonnaient jusque dans les logs de Proxmox.
🧙 Gandalf, le premier à se réveiller
Gandalf sentit le déséquilibre. Ses métriques étaient claires.
Le ceph -s parlait d’une voix saccadée.
La HA trébuchait, Nextcloud s’enlisait, et même PBS retenait ses backups, comme s’il avait peur d’écrire.
C’est alors que Daniel, l’architecte-retraité, leva les yeux de son terminal.
Il savait ce qu’il devait faire.
⚙️ Le rituel de transfert
Il brandit les outils sacrés : sgdisk, lvcreate, bluefs-bdev-migrate.
Il traça une partition parfaite sur le NVMe,
y grava une table GPT millimétrée,
et y insuffla la vie d’un nouveau volume logique.
Puis, dans un murmure de lignes de commande,
il migra les métadonnées de OSD.4,
les arrachant aux plateaux rouillés pour les loger dans la foudre.
Le pacte venait d’être scellé.
⚡ L’appel aux autres
Mais Daniel savait que ce n’était qu’un début.
Alors il lança un message, un broadcast silencieux, un ping du cœur :
« Asgard… Vishnu… À votre tour. Si vous restez ainsi, vous sombrerez. »
Et dans la nuit, les NVMe s’allumèrent.
Un à un, ils acceptèrent leur rôle :
héberger les DB, soulager les HDD, préserver le cluster.
🤝 Le Pacte
Ainsi naquit le Pacte des NVMe :
Un accord secret entre la rapidité et la capacité,
entre le silence et l’endurance,
entre l’ancienne école et la nouvelle ère.
Depuis ce jour, les graphes sont fluides,
les alertes silencieuses,
et le cluster… respire.
Et toi, Daniel, tu as prouvé que même à 61 ans,
on peut encore sauver des royaumes.
Avec un peu de bash, beaucoup de cœur,
et un SSD bien placé.
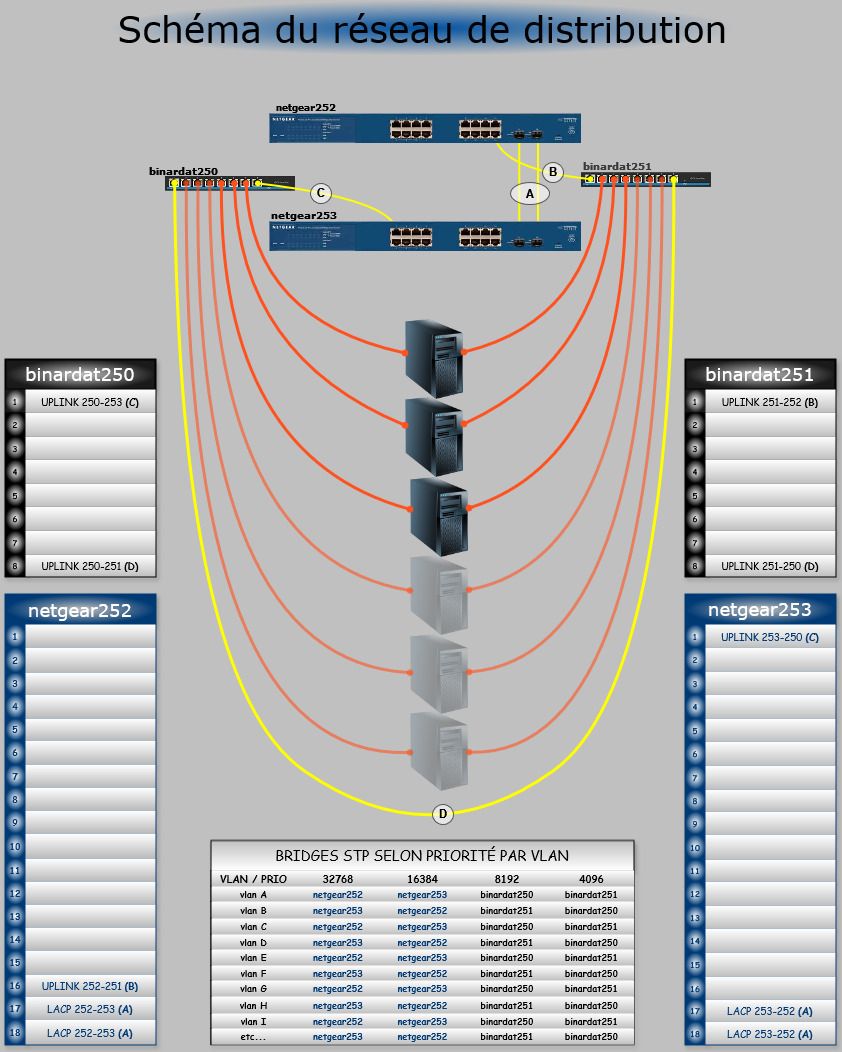
Ceph n’est pas “allergique” à balance-alb en soi, mais ALB + hyperviseur (bridge + VLANs) + switches indépendants = combo à emmerdes potentielles. D’où la reco de garder balance-tlb sur les bond qui portent Ceph.
Pourquoi ALB peut déranger un cluster Ceph (sur hyperviseurs) :
-
Réécriture ARP côté serveur (principe d’ALB) ⇒ les pairs apprennent des MAC différentes pour la même IP. Avec un bridge Linux + VLAN trunk + plusieurs pairs (OSD, MON, MDS, clients), ça peut provoquer MAC flapping / CAM churn côté switches et des rebindings réseau côté hôte.
-
Flip de chemin RX en cours de charge ⇒ re-négociations des connexions Ceph (messenger v2), micro-coupures, pics de latence, voire slow ops si ça tombe au mauvais moment.
-
Corosync partage souvent la même carte physique : les GARPs/changes d’ALB peuvent ajouter de la gigue au ring si le réseau est bien chargé.
-
Débogage pénible : symptômes sporadiques (resets, “conn reset” dans les logs Ceph), difficiles à attribuer à ALB.
Ce qui est safe et recommandé dans ton contexte :
-
Hyperviseurs Proxmox (avec OSD/MON/MDS et bridge VLAN) :
balance-tlb→ MAC stable, RX fixé, pas de magie ARP. C’est ce que tu as, et ça explique la stabilité retrouvée. -
PBS :
-
Bare-metal ou VM avec PCI passthrough de 2 NIC : là
balance-albfait sens (meilleur RX agrégé via ARP trick), et ce n’est pas un nœud Ceph → moindre risque. -
PBS en VM “classique” (vNIC virtio) : ALB dans la VM n’apporte pas d’agrégat réel (le bond TLB de l’hôte “pince” le RX sur une patte). Reste en vNIC unique bien réglée (jumbo, multiqueue) ou passe au passthrough si tu veux >10 Gb/s.
-
TL;DR
-
“Ceph allergique à ALB” = raccourci pour dire : ALB est source d’instabilité sur des hyperviseurs multi-VLAN/bridge → éviter.
-
Garde TLB sur les nœuds Ceph. Réserve ALB à un PBS bare-metal (ou VM avec passthrough), pas aux hôtes qui portent le cluster.
Résumé exécutif
Le 07-09, plusieurs VMs hébergées sur asgard (Proxmox + Ceph) ont basculé au boot en initramfs avec demande de fsck manuel. La cause racine est la disparition temporaire du NVMe qui porte la DB/WAL d’un OSD de 10 To : l’OSD a “flappé” pendant un redémarrage, générant des gels d’E/S côté RBD. Les FS ext4 des invités ont détecté des incohérences (journal à rejouer) et ont exigé une réparation interactive. Sur plusieurs VMs, fsck échouait avec des I/O errors, car les disques invités étaient rouverts en lecture seule (état de lock RBD/QEMU après le flap).
Nous avons réparé hors invité (depuis l’hôte) et tout est revenu à la normale. Aucun signe de perte de données applicatives.
Impact
-
VMs affectées (confirmées) : PBS (811), 1240, 333, 30101 ; probablement d’autres VMs du nœud asgard.
-
Symptômes :
-
Écran
(initramfs)avecfsck exited with status code 4/UNEXPECTED INCONSISTENCY. -
Sur plusieurs VMs :
Input/output error … unable to set superblock flagslors dee2fsck, et message GRUBfailure writing sector … to hd0→ disque vu RO.
-
-
Cluster Ceph : revenu rapidement en HEALTH_OK (6/6 OSD up+in) après reboot du nœud ; pas de dégradation durable.
Chronologie (approx.)
-
~08:30 : le NVMe (DB/WAL d’un OSD 10 To) disparaît, redémarrage d’asgard pour vérification BIOS/CMOS → le NVMe réapparaît.
-
08:49 : redémarrage des OSDs (logs
osd.2,osd.5), messages BlueStore de reconstruction de l’allocateur (attendu après arrêt non propre). -
Après reboot : plusieurs VMs sur asgard bootent en
initramfset/ou voient leurs disques RO. -
Journée : réparations successives (cf. “Ce qui a été fait”), retour à la normale.
Diagnostic
-
Côté invité : ext4 demande un fsck → normal après gels d’E/S.
-
Mais
fsckéchoue sur certaines VMs : I/O error → disque ouvert RO par QEMU/RBD (exclusive-lock/watchers “stuck” après le flap/snapshots tentés). -
Côté cluster : pas d’erreurs Ceph persistantes ; HEALTH_OK.
-
Conclusion : problème transitoire I/O → incohérences ext4 + état RO au niveau RBD/QEMU à lever.
Cause racine
-
Disparition/re-apparition du NVMe DB/WAL d’un OSD (câble/slot/firmware/APST/PCIe power-states) ⇒ freeze d’E/S sur certaines images RBD ⇒ ext4 marque le FS “dirty” et bloque au boot.
-
Contribuant : locks RBD/watcher résiduels (exclusive-lock) après les flaps/snapshots, amenant QEMU/ISO à rouvrir le disque en RO, empêchant
fsckd’écrire le superblock.
Ce qui a été fait (remédiation)
-
Stabilisation cluster : vérification
ceph -s(HEALTH_OK). Utilisation temporaire denooutpendant certaines manips (puis unset). -
VM 333 :
-
rbd map→partprobe(création/dev/rbd0p*) →e2fsck -f -y /dev/rbd0p2(ext4) →rbd unmap→qm start 333. ✅
-
-
VM PBS (811) :
-
rbd map→ activation du VG pbs malgré le filtre LVM (--config 'devices { global_filter = … }') →e2fsck -f -y /dev/pbs/root(erreurs corrigées) →vgchange -an→rbd unmap→qm start 811. ✅
-
-
VM 1240 : même approche (host-side fsck) après essais initramfs/ISO infructueux. ✅
-
VM 30101 : ext4 direct sur
/dev/rbd0p1+ EFI vfat surp15→e2fsckpuis reboot. ✅ -
Contrôles : services PBS up, verify/GC, Ceph HEALTH_OK.
Risque données
-
Faible. ext4 a été réparé par
e2fsck(journal rejoué, compteurs corrigés). Pas de corruption applicative observée. PBS a redémarré proprement et les datastores sont lisibles.
Actions correctives & préventives (recommandées)
Matériel/OSD (cause racine)
-
NVMe (DB/WAL) :
-
Vérifier firmware et santé :
nvme smart-log,smartctl -a,dmesg | egrep -i 'nvme|pcie|AER|timeout|reset'. -
Désactiver APST/profondeurs d’économie si contrôleur capricieux : ajouter sur asgard
nvme_core.default_ps_max_latency_us=0(GRUB) puis redémarrage planifié. -
Miroir/RAID1 pour DB/WAL si possible (éviter le SPOF d’un seul NVMe).
-
-
Procédures maintenance Ceph :
-
ceph osd set nooutavant intervention, unset juste après. -
Scripting de check : refuser tout reboot si
ceph health≠ OK.
-
Invités/VMs
-
Auto-réparation au boot (Ubuntu/Debian) :
fsck.mode=force fsck.repair=yesdansGRUB_CMDLINE_LINUX_DEFAULT+update-grub.
⇒ la VM répare seule et ne s’arrête plus en initramfs. -
Runbook “host-side fsck” (3 lignes) pour futures urgences :
qm stop <id>; rbd map <pool>/<img>; partprobe /dev/rbdX; \ vgchange -ay; e2fsck -f -y <LV ext4 ou /dev/rbdXpY>; vgchange -an; \ rbd unmap /dev/rbdX; qm start <id> -
Snapshots :
-
Limiter les snapshots “long terme” (1–3 max / VM) ; privilégier PBS pour la rétention.
-
Supprimer les vieux snapshots en heures creuses.
-
Supervision/alerting
-
Alerte sur disque NVMe manquant (SMART/PCIe), et sur flags Ceph (noout/noup laissés actifs).
-
Alerte sur VM en boot loop/initramfs (via Proxmox API + syslog).
Leçons apprises
-
Un flap DB/WAL peut suffire à faire geler des invités malgré un cluster vite “green”.
-
Quand
fsckéchoue en I/O depuis l’invité, réparer depuis l’hôte (map RBD +e2fsck) est rapide et fiable. -
Ne pas oublier d’unset
nooutet de nettoyer les snapshots pris pendant l’incident.
État final
-
Ceph : HEALTH_OK.
-
PBS (811) et VMs concernées : opérationnelles.
-
Données : pas d’incohérences observées après
e2fsck.
Utilisation express
1) chmod +x host-fsck.sh
2) réparer une VM (exemples)
:
./host-fsck.sh 333
./host-fsck.sh 811 --efi # lance aussi fsck.vfat sur l’EFI si trouvé
Le script :
-
stoppe la VM,
-
lève les locks RBD résiduels,
-
mappe l’image (avec les bons creds du storage),
-
crée les devices de partitions,
-
détecte la racine (ext4 directe ou via LVM) et lance
e2fsck -f -y, -
(optionnel) répare l’EFI en vfat,
-
nettoie et redémarre la VM.
#!/usr/bin/env bash
# host-fsck.sh — Réparer un système de fichiers d'une VM Proxmox stockée sur Ceph RBD
# Exécuter sur l'hôte Proxmox. Répare la racine ext4 (ou via LVM) et redémarre la VM.
# Usage: ./host-fsck.sh <VMID> [--efi]
# --efi : tente aussi un fsck.vfat sur la partition EFI si détectée
#
# Notes:
# - Tolère l'absence de "kpartx" (utilise partprobe à la place).
# - Gère les locks RBD résiduels (blocklist automatique des watchers).
# - Contourne le filtrage LVM sur /dev/rbd* via --config local.
# - N'interrompt PAS sur e2fsck non‑zéro (1=errors corrected, etc.).
set -uo pipefail
RED=$'\e[31m'; GRN=$'\e[32m'; YLW=$'\e[33m'; BLU=$'\e[34m'; CLR=$'\e[0m'
msg() { echo "${BLU}[*]${CLR} $*"; }
ok() { echo "${GRN}[ok]${CLR} $*"; }
warn(){ echo "${YLW}[!]${CLR} $*"; }
err() { echo "${RED}[x]${CLR} $*" >&2; }
die() { err "$*"; exit 1; }
[[ $EUID -eq 0 ]] || die "Doit être exécuté en root sur l'hôte Proxmox."
[[ ${1:-} ]] || die "Usage: $0 <VMID> [--efi]"
VMID=$1; shift || true
DO_EFI=false
while [[ ${1:-} ]]; do
case "$1" in
--efi) DO_EFI=true;;
*) die "Option inconnue: $1";;
esac
shift || true
done
# 1) Stopper la VM
msg "Arrêt de la VM $VMID"
qm stop "$VMID" >/dev/null 2>&1 || true
sleep 1
# 2) Trouver le disque de boot (ordre de préférence)
DISK_LINE=$(qm config "$VMID" | awk '/^(scsi0|virtio0|sata0|ide0):/{print; exit}')
if [[ -z "$DISK_LINE" ]]; then
DISK_LINE=$(qm config "$VMID" | awk '/^(scsi|virtio|sata|ide)[0-9]+:/{print; exit}')
fi
[[ -n "$DISK_LINE" ]] || die "Impossible de déterminer le disque de la VM (qm config)."
STORAGE=$(sed -nE 's/^[^ ]+: ([^:]+):([^,]+).*/\1/p' <<<"$DISK_LINE")
IMAGE=$( sed -nE 's/^[^ ]+: ([^:]+):([^,]+).*/\2/p' <<<"$DISK_LINE")
[[ -n "$STORAGE" && -n "$IMAGE" ]] || die "Stockage ou image introuvable dans: $DISK_LINE"
# 3) Résoudre le pool/credentials depuis /etc/pve/storage.cfg
SCFG=/etc/pve/storage.cfg
[[ -r $SCFG ]] || die "Fichier $SCFG introuvable."
POOL=$(awk -v s="$STORAGE" '$1=="rbd:"&&$2==s{f=1;next} f&&$1=="pool"{print $2; exit} f&&/^rbd:/{f=0}' "$SCFG")
MONHOST=$(awk -v s="$STORAGE" '$1=="rbd:"&&$2==s{f=1;next} f&&$1=="monhost"{print $2; exit} f&&/^rbd:/{f=0}' "$SCFG")
RBDUSER=$(awk -v s="$STORAGE" '$1=="rbd:"&&$2==s{f=1;next} f&&$1=="username"{print $2; exit} f&&/^rbd:/{f=0}' "$SCFG")
KEYRING=$(awk -v s="$STORAGE" '$1=="rbd:"&&$2==s{f=1;next} f&&$1=="keyring"{print $2; exit} f&&/^rbd:/{f=0}' "$SCFG")
[[ -n "$POOL" ]] || die "Pool Ceph non trouvé pour le storage '$STORAGE' dans $SCFG."
ok "Disque: $POOL/$IMAGE (storage=$STORAGE)"
# 4) Lever d'éventuels watchers (locks) RBD
msg "Recherche de watchers RBD (locks)"
WATCHERS=$(rbd status "$POOL/$IMAGE" 2>/dev/null | awk -F'[= ]' '/watcher=/{print $2}') || true
if [[ -n "$WATCHERS" ]]; then
warn "Watchers détectés: $WATCHERS → blocklist"
while read -r w; do [[ -n "$w" ]] && ceph osd blocklist add "$w" || true; done <<<"$WATCHERS"
else
ok "Aucun watcher résiduel"
fi
# 5) Mapper l'image RBD
msg "Mapping RBD ($POOL/$IMAGE)"
DEV=""
DEV=$(rbd map "$POOL/$IMAGE" 2>/dev/null || true)
if [[ -z "$DEV" ]]; then
warn "Mapping simple échoué → tentative avec credentials de $STORAGE"
[[ -n "$MONHOST" && -n "$RBDUSER" && -n "$KEYRING" ]] || die "Credentials incomplets pour $STORAGE"
DEV=$(rbd -m "$MONHOST" --id "$RBDUSER" --keyring "$KEYRING" map "$POOL/$IMAGE")
fi
[[ -b "$DEV" ]] || die "Échec du mapping RBD."
ok "Image mappée: $DEV"
# 6) Exposer les partitions (partprobe ou kpartx)
if command -v kpartx >/dev/null 2>&1; then
kpartx -av "$DEV" >/dev/null || true
else
partprobe "$DEV" || true
fi
sleep 1
# 7) Détecter la racine
msg "Détection des partitions/FS"
PARTS=( $(ls ${DEV}p* 2>/dev/null || true) )
[[ ${#PARTS[@]} -gt 0 ]] || warn "Aucune partition ${DEV}p*; (image sans table de partitions?)"
ROOT_DEV=""; EFI_DEV=""; PV_DEV=""
if [[ ${#PARTS[@]} -gt 0 ]]; then
while read -r line; do
dev=$(cut -d: -f1 <<<"$line"); typ=$(sed -nE 's/.*TYPE="([^"]+)".*/\1/p' <<<"$line")
case "$typ" in
ext4|ext3|ext2) [[ -z "$ROOT_DEV" ]] && ROOT_DEV="$dev" ;;
vfat) [[ -z "$EFI_DEV" ]] && EFI_DEV="$dev" ;;
LVM2_member) PV_DEV="$dev" ;;
esac
done < <(blkid ${DEV}p* 2>/dev/null)
fi
# 8) Si racine en LVM
VG_NAME=""; LV_ROOT=""
if [[ -z "$ROOT_DEV" && -n "$PV_DEV" ]]; then
msg "Racine probable dans LVM ($PV_DEV)"
VG_NAME=$(pvs --config 'devices { global_filter = [ "a|'"$PV_DEV"'|", "r|.*|" ] }' -o vg_name --noheadings 2>/dev/null | awk 'NF{print $1; exit}')
[[ -n "$VG_NAME" ]] || die "Impossible de déterminer le VG sur $PV_DEV"
msg "Activation du VG $VG_NAME"
vgchange --config 'devices { global_filter = [ "a|/dev/rbd.*|", "r|.*|" ] }' -ay "$VG_NAME" >/dev/null
# Cherche un LV root non-swap
while read -r path name; do
[[ "$name" == swap* ]] && continue
if [[ "$name" == root* || -z "$LV_ROOT" ]]; then LV_ROOT="$path"; fi
done < <(lvs --config 'devices { global_filter = [ "a|/dev/rbd.*|", "r|.*|" ] }' -o lv_path,lv_name "$VG_NAME" --noheadings)
[[ -n "$LV_ROOT" ]] || die "LV racine introuvable dans VG $VG_NAME"
fi
TARGET=${ROOT_DEV:-$LV_ROOT}
[[ -n "$TARGET" ]] || die "Aucune cible ext4 trouvée."
ok "Cible FS: $TARGET"
# 9) e2fsck (ne pas quitter sur code non‑zéro)
msg "e2fsck -f -y $TARGET (peut prendre du temps)"
set +e
E2OUT=$(e2fsck -f -y "$TARGET" 2>&1)
E2RC=$?
set -e
echo "$E2OUT"
if (( E2RC & 4 )); then
warn "e2fsck a rencontré des erreurs non corrigées (rc=$E2RC)."
else
ok "e2fsck terminé (rc=$E2RC)."
fi
# 10) EFI (optionnel)
if $DO_EFI && [[ -n "$EFI_DEV" ]]; then
msg "fsck.vfat -a $EFI_DEV"
fsck.vfat -a "$EFI_DEV" || warn "fsck.vfat a retourné un code non‑zéro"
fi
# 11) Nettoyage
msg "Nettoyage"
if [[ -n "$VG_NAME" ]]; then
vgchange --config 'devices { global_filter = [ "a|/dev/rbd.*|", "r|.*|" ] }' -an "$VG_NAME" >/dev/null
fi
if command -v kpartx >/dev/null 2>&1; then kpartx -dv "$DEV" >/dev/null || true; fi
rbd unmap "$DEV" >/dev/null || true
# 12) Redémarrage de la VM
msg "Démarrage de la VM $VMID"
qm start "$VMID" >/dev/null && ok "VM $VMID démarrée" || warn "Échec du démarrage VM $VMID (vérifier la console)"
exit 0
Maintenance & configurations
Stratégie d’adressage IP “multi-tenant” propre, prédictible et prête pour Proxmox SDN (VLAN/VXLAN), avec micro-segmentation par défaut.
Voici le modèle générique et une instance pour le tenant Chezlepro.
1) Principes (simples et solides)
-
Séparation stricte par tenant via VRF (ou au minimum par zone SDN).
-
Adressage déterministe: mêmes règles partout → facile à raisonner, à automatiser (Terraform/Ansible) et à dépanner.
-
IPv4 + IPv6 ULA (RFC4193) dès le départ.
-
Zéro-trust: inter-tenant DENY par défaut; seules des exportations contrôlées vers un VRF “Shared-Services”.
-
Éléments communs (DNS/NTP/PKI/Logs/Jump) dans un VRF commun avec listes d’accès très serrées.
-
Éviter les collisions: on privilégie 172.16.0.0/12 pour les overlays tenant; on évite 192.168/10.0 trop utilisés à la maison/chez les clients.
2) Réservations globales (plateforme)
-
Underlay (physique, liens inter-nœuds, L3 fabric)
-
172.27.0.0/16 (P2P en /31 ou /30 entre nœuds/switchs/routeurs)
-
-
Mgmt & HA Proxmox (hors tenant)
-
172.28.0.0/24 (GUI, SSH, corosync, etc.)
-
-
Ceph (garde ton existant si déjà en prod)
-
Public: 172.28.10.0/24
-
Cluster: 172.28.20.0/24
-
-
Backup/Replication (vers Technolibre/partenaire)
-
172.28.30.0/24
-
-
Shared-Services (VRF=shared)
-
172.22.0.0/16 (DNS, NTP, PKI, Syslog/ELK, Jump/Bastion, Registry, Git/CI, SMTP relay…)
-
IPv6 ULA:
fd5a:0000:0000::/48
-
Ces blocs “plateforme” ne sont pas routés vers Internet; egress/ingress passent par ton firewall de périmètre si nécessaire.
3) Pool des tenants (overlay SDN)
-
IPv4 tenants: 172.16.0.0/12 (172.16.0.0–172.31.255.255)
-
1 tenant = 1 /16:
172.16.<TenantID>.0/16(TenantID ∈ 0..255)
-
-
IPv6 ULA par tenant (RFC4193, stable et offline-friendly)
-
Préfixe maître ULA:
fd5a:xxxx:yyyy::/48 -
Formule:
fd5a:0000:<TenantID hex>::/48-
ex. Tenant 100 (0x64) →
fd5a:0000:0064::/48
-
-
Avantages: 1 /16 par tenant = énorme marge, simple à mémoriser; /24 par VNet = raisonnable et lisible.
4) Découpage interne d’un tenant (gabarit)
Dans le /16 du tenant, on normalise le 3e octet par “rôle” (VNet). Exemple de codes de segments:
| Segment (VNet) | /24 | Usage typique |
|---|---|---|
| 10 – admin | x.10.0/24 | Bastions, outils d’admin, RMM |
| 20 – web/front | x.20.0/24 | Frontends web/app |
| 30 – app | x.30.0/24 | Services applicatifs |
| 40 – db | x.40.0/24 | Bases de données |
| 50 – msg/cache | x.50.0/24 | MQ, Redis, memcached |
| 60 – ci/cd | x.60.0/24 | Runners, builders |
| 70 – dev | x.70.0/24 | Dev/feature env |
| 80 – stage | x.80.0/24 | Pré-prod |
| 90 – dmz | x.90.0/24 | Publication/edge |
| 100 – udp/mcast | x.100.0/24 | UDP/multicast (vmxnet/virtio, tests perf) |
| 200 – réserves | x.200.0/24.. | Croissance |
Chaque /24 = un VNet SDN (VXLAN/EVPN) ou un VLAN.
GW par VNet (si L3 distribué) =.1(ex. 172.16.100.20.1 pour web).
5) Encodage VLAN/VNI (propre et borné)
-
VLAN ID =
1500 + TenantID (0..255) + (segment/10)→ garde tout < 4094-
Chezlepro (TID=100):
-
admin(10) → VLAN 1600
-
web(20) → 1610
-
app(30) → 1620 …
-
-
-
VNI (VXLAN) =
10000 + VLAN(lecture directe en opé)
6) Règles de sécurité (par défaut)
-
VRF tenant:
deny allinter-VNet; n’ouvrir que les flux nord-sud nécessaires. -
Exports vers Shared-Services:
-
Tenants → DNS/NTP/PKI/Logs/Repo uniquement (ports précis).
-
-
No east-west entre tenants (VRF isolés), sauf contrat explicite (peering applicatif).
-
Egress Internet: via VRF-egress contrôlé (NAT/policy), idéalement par VNet (web/dmz seulement).
7) DHCP / IPAM / DNS
-
IPAM central (Proxmox IPAM, NetBox ou phpIPAM): source de vérité.
-
DHCP par VNet (ou IP statiques via cloud-init/Ansible pour serveurs).
-
DNS split-horizon:
-
svc.shared.local.pour services partagés, -
*.chezlepro.local.pour ton tenant (interne), -
domaines publics gérés séparément (reverse proxy/ACME à la bordure).
-
8) Exemple complet — Tenant “Chezlepro” (TID = 100)
-
IPv4 tenant:
172.16.100.0/16 -
IPv6 ULA:
fd5a:0000:0064::/48
| VNet (segment) | VLAN | VNI | IPv4 /24 | IPv6 /64 | GW | Notes |
|---|---|---|---|---|---|---|
| admin (10) | 1600 | 11600 | 172.16.100.10.0/24 | fd5a:0:64:10::/64 | .10.1 | Bastions, mgmt tools |
| web (20) | 1610 | 11610 | 172.16.100.20.0/24 | fd5a:0:64:20::/64 | .20.1 | Fronts HTTP(S) |
| app (30) | 1620 | 11620 | 172.16.100.30.0/24 | fd5a:0:64:30::/64 | .30.1 | Backends |
| db (40) | 1630 | 11630 | 172.16.100.40.0/24 | fd5a:0:64:40::/64 | .40.1 | SGBD |
| msg/cache (50) | 1640 | 11640 | 172.16.100.50.0/24 | fd5a:0:64:50::/64 | .50.1 | MQ/Redis |
| dev (70) | 1660 | 11660 | 172.16.100.70.0/24 | fd5a:0:64:70::/64 | .70.1 | DEV |
| stage (80) | 1670 | 11670 | 172.16.100.80.0/24 | fd5a:0:64:80::/64 | .80.1 | PREPROD |
| dmz (90) | 1680 | 11680 | 172.16.100.90.0/24 | fd5a:0:64:90::/64 | .90.1 | Publication |
| udp/mcast(100) | 1690 | 11690 | 172.16.100.100.0/24 | fd5a:0:64:100::/64 | .100.1 | UDP/vmxnet tests |
Flux autorisés (exemples de SG Proxmox):
-
sg-web-egress: web→ANY TCP 80,443 + DNS→shared (53/udp,tcp) -
sg-web-to-app: web→app TCP 8080/8443 -
sg-app-to-db: app→db TCP 5432/3306 -
sg-admin-any: admin→{web,app,db} TCP 22,443 -
sg-deny-all: DROP ANY→ANY (fin de chaîne)
9) Intégration Proxmox SDN (pas-à-pas)
-
Zone SDN
fabric01(VXLAN) sur tonbond10(MTU 9000 si possible). -
VNets: créer
vnet-cpl-admin,vnet-cpl-web, … (un par ligne du tableau) avec leur VNI et /24. -
Gateways: activer la passerelle L3 par VNet (ou phase 1: transiter par ton firewall de bordure).
-
Firewall distribué: activer au niveau Datacenter/Cluster, créer Aliases/SG ci-dessus, politique deny par défaut, attacher SG aux VNets/VMs.
10) Peering / inter-tenant (si un jour nécessaire)
-
Toujours via un VRF de transit + ACL nominatives (liste d’IP/ports).
-
Jamais de routage global entre tenants.
-
Journaliser (syslog) et monitorer (Icinga/Prometheus) tous les flux de peering.
11) Nommage & étiquettes (pour ton IaaS)
-
VNets:
vnet-<tenant>-<role>(ex.vnet-cpl-web) -
Tags VM:
tenant=cpl,env=prod|dev|stage,role=web|app|db -
DNS:
<name>.<env>.cpl.local(ex.api.prod.cpl.local)
Si tu veux, je te fournis:
-
un fichier IPAM .csv prêt à importer (tous les sous-réseaux & réservations),
-
un jeu de Security Groups Proxmox à coller,
-
et la déclinaison pour un second tenant (ex. “Client-A” avec TID=101) pour valider la reproductibilité.
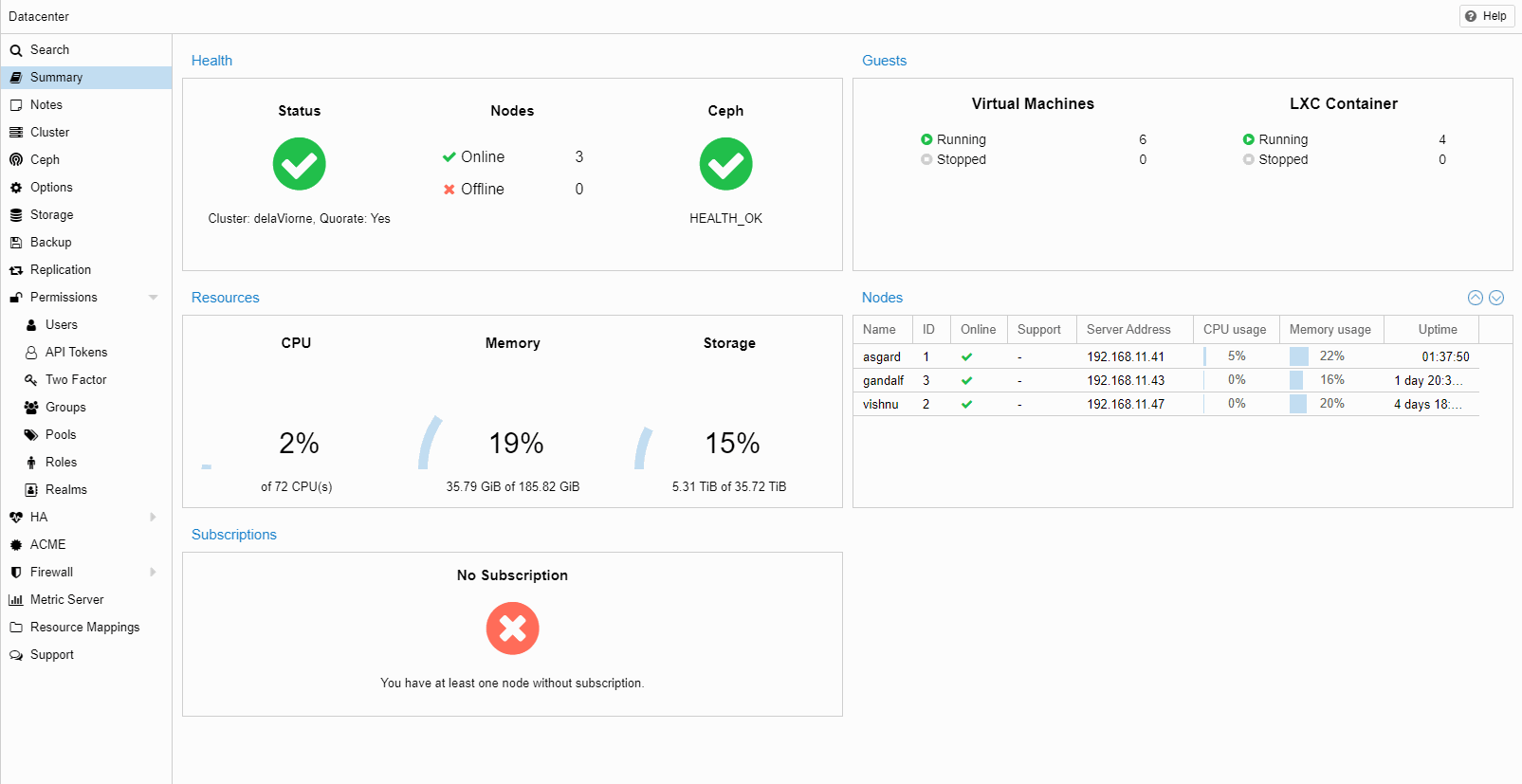
Version du noyau Linux : Linux 6.2.16-3-pve #1 SMP PREEMPT_DYNAMIC PVE 6.2.16-3
Version PVE Manager : pve-manager/8.0.3
Installé à partir du DVD : Proxmox VE 8.0 ISO Installer
INTERNE
-
Support : Stockage Raid du serveur Corsair
-
Type de sauvegarde : Complète
-
Fréquence : Quotidienne
-
Conservation : 3 jours, 3 semaines, 3 mois, 1 an
-
Données sauvegardées : VM et conteneurs LXC sélectionnés
EXTERNE
-
Support : Stockage Raid du serveur Big2
-
Type de sauvegarde : Complète
-
Fréquence : Quotidienne
-
Conservation : 3 jours, 3 semaines, 3 mois, 1 an
-
Données sauvegardées : Tous les conteneurs LXC, VM et modèles
1. Retirer un serveur de la grappe
2. Réseau full meshed pour CEPH
3. Déménager les réseaux CEPH sur du 10G
4. Réduire la taille d'un disque virtuel
5. Préparer un hyperviseur pour ansible :
adduser ansible
adduser ansible sudo
printf "ansible ALL=(ALL) NOPASSWD:ALL\n" >/etc/sudoers.d/90-ansible && chmod 0440 /etc/sudoers.d/90-ansible
Devis matériel & schémas
Carte-mère : ASUS TUF GAMING X670E-PLUS
CPU(s) : 24 x AMD Ryzen 9 7900X 12-Core Processor (1 Socket)
Mémoire vive (RAM) : 64Gb (2 X Corsair Vengeance 32Gb DDR5 5600)
Espace-disque : 500Gb Western Digital Blue NVMe SN570
2To Western Digital NVMe M.2
10To Western Digital RED Plus
Carte réseau : 4 Ports 2.5G PCIe Binardat RTL8125B
Carte-mère : ASUS TUF GAMING X670E-PLUS
CPU(s) : 24 x AMD Ryzen 9 7900X 12-Core Processor (1 Socket)
Mémoire vive (RAM) : 64Gb (2 X Corsair Vengeance 32Gb DDR5 5600)
Espace-disque : 512Gb Samsung SSD 850 PRO
2To Western Digital NVMe M.2
10To Western Digital RED Plus
Carte réseau : 4 Ports 2.5G PCIe Binardat RTL8125B
Carte-mère : ASUS TUF GAMING X670E-PLUS
CPU(s) : 24 x AMD Ryzen 9 7900X 12-Core Processor (1 Socket)
Mémoire vive (RAM) : 64Gb (2 X Corsair Vengeance 32Gb DDR5 5600)
Espace-disque : 500Gb Samsung SSD 850 EVO
2To Western Digital NVMe M.2
10To Western Digital RED Plus
Carte réseau : 4 Ports 2.5G PCIe Binardat RTL8125B